Enno日本語エラーチェックの仕様について説明します。サービス内容は今後変更の可能性があります。
情報の保護
チェックする文章が外部に漏れないように配慮しています。
-
チェックされた文章は、一切データベースに保存しません。
-
チェックされた文章は、Googleなどの検索エンジンに保存されることもありません。
-
チェックされた文章は、サーバーのログにも出力していません。ただしホスティングサービス側のログで一定期間保存されている可能性はあります(Enno運営側からは参照できません)。
-
サイトへの通信はSSL証明書によって暗号化されています。これは安全性を高めるためのものであり、ネットに送信すべきでない文章の送信を許すためのものではありません。
対象言語
基本的に現代日本語を対象とします。現代日本語には日本語のひらがな・カタカナ・漢字・各種記号の他に、主に英語の単語・記号、そして数字が含まれることを前提とします。
-
New:-
2014年10月より、Wikipedia: Lists of common misspellingsに掲載されている英語スペルミスデータをenno.jpにインポートし、日本語に含まれる英語のスペルミスも本格的にチェックできるようになりました。
英語のスペルミスチェックは、日本語の文章に含まれる英単語を対象とします。日本語を含まない英文のスペルチェックや文法チェックには、より機能の豊富な専用のチェッカをお使いください。
登録したスペルミスは英語を対象としているため、英語以外のアルファベット言語で誤検出が発生する可能性があります。
対象となる文章
チェック対象となる文は、 現代日本語で書かれたフォーマルな文章 (出版物全般、公式文書、ビジネス文書、ビジネスメール、法務文書、特許文書、マニュアル、論文、ニュース記事、エッセイ、改まった手紙など) を想定しています。業種、分野、文脈は基本的に限定しません。
-
ここで言う現代日本語文には、ひらがな、カタカナ、漢字、約物 (句読点、かっこなど) の他に、英数字と記号 (いわゆるASCII文字)を相当量、その他のUTF-8文字を若干含むことを前提としています。
-
造語やネットのハンドル名やアスキーアートなどを含む文、会話文、ト書き、マンガの台詞、小説、詩/俳句/和歌/連歌、くだけた口調の日記、古文、旧仮名遣い、言葉遊びや駄洒落を交えたエッセイ、ひらがなの多い小学生向けの文、コピーなどの宣伝文、ユーザーインターフェイス文字列のような断片的な言葉については優先度を下げています。チェック自体は行えますが、誤検出が増える可能性があります。
-
いわゆる禁止用語はチェックしません。今後も行なう予定はありません。
検出するエラー
出版業界で行われているいわゆる「校正」よりも範囲が狭いことにご注意ください。別途校正ツールと併用可能です。
- タイポ、変換ミス、誤字脱字
- 主要な検出対象です。
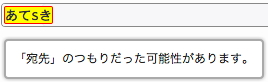
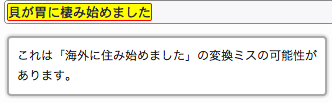
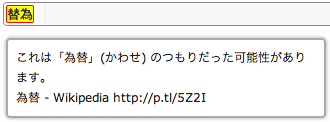
- 全角文字の約物エラー
- 全角の句点、読点、かっこなどの約物のエラーチェックです。半角文字の約物 (パンクチュエーション) については、ソースコードで不要なエラーを出さない範囲でチェックします。
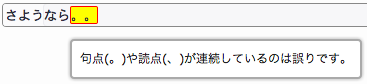
- 末尾スペースエラー
- 段落末尾のスペースチェックです。ソースコードで不要なエラーを出さないため、文頭および文中の連続スペースについてはデフォルトでは扱っていません。

検出結果について
パターンが登録されているエラーのみを検出します。
-
登録されていないエラーは検出できません。エラーが多数登録されることで機能が強化されます。応募フォームにて皆様からのエラー応募をお待ちしています。
-
誤検出があった場合、同じ応募フォームでお知らせください。対応いたします。
-
誤検出をなるべく回避するため、可能な場合にはエラーの前後の文字を含めるようにしています。その分多くのパターンを登録する必要があります。
-
ある箇所でエラーが二重に発生している場合、一度のチェックでは2つのエラーのうち一方のみが検出されます。このため、あるエラーを修正して再度チェックすると、同じ箇所に別のエラーが表示されることがあります。
-
このサービスに完成はありません。誤検出を減らし、より多くのエラーを検出できるよう、既存のパターンにも常に見直しをかけています。
ソースコードを含む文章
チェックされるすべての文字をエスケープしているので、プログラミング言語やHTMLなどのコードを含む文章も扱えます。
-
英数字に対するチェックは末尾スペースチェックなど最低限しか行なっていないので、コード部分での誤検出を抑えています。
-
UTF-8で統一していますので、日本語や英数字以外の文字を含んでいても扱えます。
-
理工系の文章で広く用いられている全角の句読点「,」(U+FF0C)「.」(U+FF0E)。にも対応しています。ただし、英文で使用されているのと同じ半角の「,」「.」を日本語の句読点として使用しているものには対応していません(誤検出、検出漏れの可能性があります)。
-
タブ文字は左のチェック結果からは消えます。右フォーム内のタブはチェック後も保存されます。
-
チェックの性質上、文の途中で改行が挿入されている文章(メール用に80文字ずつ改行された文など)では大量に誤検出が発生する可能性があり、不向きです。事前に改行を取り除いておく必要があります。
エラーの範囲について
エラーとして扱うのは、ほぼどのような文脈においても誤りである可能性が高いものに限っています。議論の余地を残すものは扱いません。
-
文体に属する違い(だ・である調、です・ます調など)はエラーとして扱いません。
-
「インターフェイス」と「インタフェース」、「ベートーヴェン」と「ベートーヴェン」、「進む」と「すすむ」、「行う」と「行なう」のようなカタカナ表記/漢字表記/送り仮名の違い(表記揺れ)は扱いません。
-
句読点が全角であるか半角であるかなどの、スタイルの違いは扱いません。
-
特定の業種または分野のみで通用する言葉や、分野や文脈によって表記などが異なる言葉については、他のチェックに影響が生じる場合は扱いません。
-
技術上、または言語の性質上本質的に検出不可能な誤りについては対象外とします。たとえば数字の間違いは機械的なチェックが不可能です。最終的には校正の専門家によるチェックが不可欠です。
-
エラーを多数登録することで検出率を向上させることのみ可能です。